
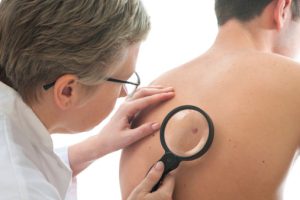
במאמר שפורסם בכתב העת The Lancet Oncology מדווחים חוקרים על תוצאות מחקר חדש, מהן עולה כי אלגוריתם לימוד-מכונה הוביל להערכה טובה יותר של נגעים עוריים פיגמנטריים, בהשוואה להערכה שבוצעה ע”י רופאים מומחים.
במסגרת המחקר ביקשו החוקרים להשלים השוואה של הדיוק האבחנתי של מערכות חדשות של אלגוריתם לימוד-מכונה אל מול הערכה של רופאים מומחים של נגעים עוריים פיגמנטריים שפירים וממאירים.
לצורך המחקר התבקשו רופאים לאבחן הדמיות דרמטוסקופיות שנבחרו באקראי בקבוצות של 30 הדמיות מסדרה של 1,511 תמונות. האבחנות של רופאים נבחנו אל מול אלו של 139 אלגוריתמים שנוצרו ע”י 77 מעבדות לימוד-מכונה, אשר לקחו חלק באתגר International Skin Imaging Collaboration לשנת 2018 לאחר השלמת סדרת אימון של 10,015 תמונות מוקדם יותר. הנגעים סווגו לאחת משבע קטגוריות: קרצינומה תוך-אפיתליאלית, כולל Actinic Keratoses ו-Bowen’s Disease; Basal Cell Carcinoma; נגעים קרטינוציטיים שפירים, כולל Solar Lentigo, Seborrheic Keratosis ו-Lichen planus-like Keratosis; דרמטופיברומה; מלנומה; נבוס מלנוציטי; ונגעים וסקולאריים.
שני התוצאים העיקריים היו ההבדלים במספר האבחנות הספציפיות הנכונות בכל מקבץ, בין פרשנות כל הרופאים ושלושת האלגוריתמים המובילים, ובין פרשנות הרופאים המומחים ושלושת האלגוריתמים המובילים.
בתקופה שבין תחילת אוגוסט, 2018, ועד סוף ספטמבר, 2018, ניסו 511 רופאים מ-63 מדינות לפחות פעם אחת לבחון את ההדמיות. 283 מבין 511 הרופאים (55.4%) היו מומחים ברפואת עור, 118 (23.1%) היו מתמחים ברפואת עור ו-83 (16.2%) היו רופאים כלליים.
בהשוואת ההערכות של כלל הרופאים אל מול כל האלגוריתמים המבוססים על לימוד-מכונה נמצא כי המערכות האוטומטיות הובילו לאבחנות נכונות יותר ב-2.01 מקרים, בממוצע (17.91 לעומת 19.92). עוד מדווחים החוקרים כי 27 רופאים מומחים, עם למעלה מעשר שנות ניסיון, השיגו בממוצע 18.78 תשובות נכונות, זאת בהשוואה ל-25.43 תשובות נכונות מצד שלושת האלגוריתמים המובילים (p<0.0001).
החוקרים מציינים כי למרות שממצאי המחקר מעידים על תוצאות טובות יותר למערכת לימוד-מכונה בהערכת נגעים עוריים, יש לקחת בחשבון את מגבלות הטכנולוגיה.












השאירו תגובה
רוצה להצטרף לדיון?תרגישו חופשי לתרום!